Ich lese gerade ein Studie und bin ein wenig verwirrt, was die Herren da eigentlich gemacht haben.
Es ist eine Studie mit 2 messwiederholten Faktoren, mit zwei bzw. drei Stufen. Die Forscher haben nun die Versuchspersonen (n = 10) als Between-Faktor in die ANOVA mit hineingenommen, so dass es eine 10x2x3-ANOVA ist. Irgendwie habe ich das Gefühl, dass das gar keinen Sinn macht, da die Unterschiede zwischen den Versuchspersonen doch eh schon durch die Messwiederholung berücksichtigt werden, oder?
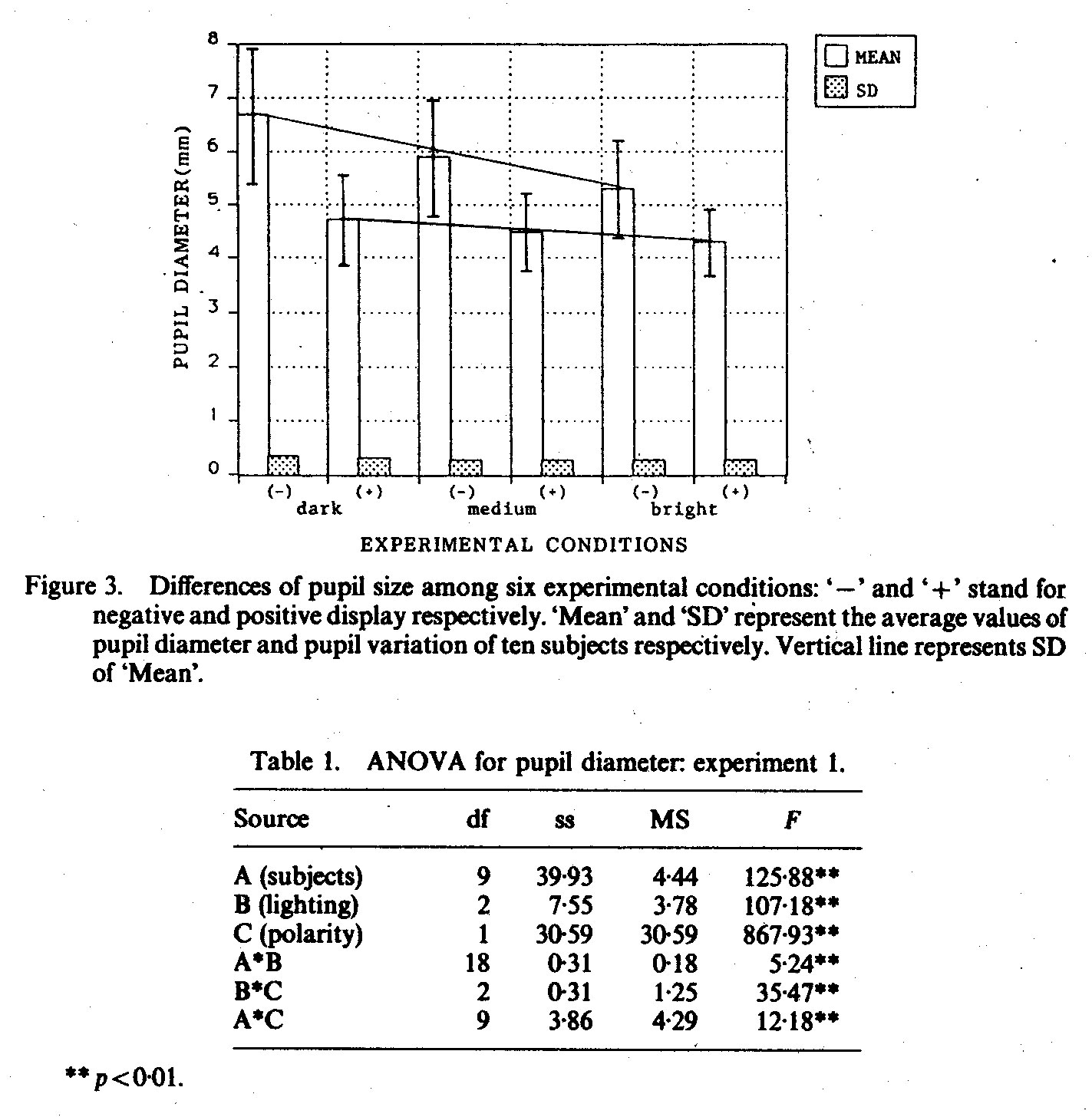
Aus einer Abbildung geht hervor, dass die AV mit dem Standardfehler korreliert ist (hohe Ausprägung der AV geht mit großem Standardfehler einher). Hat dies irgendwelche Ausirkungen auf die Validität der Ergebnisse? Habe ich es richtig verstanden, dass der SF des Mittelwerts angibt, wie stark der empirische Mittelwert vom Populationsmittelwert abweicht, also im Endeffekt die Reliabilität der Schätzung angibt?
Solange, bis JPL und ML qualifiziertere Antworten geben, will ich’s probieren:
Wenn man die Subjekte als eigenen Faktor in die ANOVA aufnimmt, dann werden die Subjekt-bedingten Varianzen eben diesem Faktor zugeordnet und somit aus dem Rest rausgerechnet. Damit entspricht das einer ANOVA mit Meßwiederholung. Man bekommt so zwar einen F-Wert auch für den Subjekt-Faktor, aber der interessiert nicht weiter, weil man ja sowieso Unterschiede zwischen den Subjekten erwartet.
Eine Voraussetzung für die ANOVA ist, dass die Fehler normalverteilt sind und nicht mit der AV korrelieren. Tun sie das, spricht man von Heteroskedastizität. Für die ANOVA kann man Abweichungen von der Varianzhomogenität leicht mit Bartlett’s Test testen.
Und: Ja, der Standardfehler schätzt die Standardabweichung der Mittelwerte. Je kleiner, desto präziser ist der wahre Mittelwert bestimmt. Gemäß dem Zentralen Grenzwertsatz und den Eigenschaften der Normalverteilung liegt der wahre Mittelwert mit ca. 63%iger Wahrscheinlichkeit im Intervall M-SE und M+SE (M=Mittelwert, SE=Standardfehler).
Es ist eine Studie mit 2 messwiederholten Faktoren, mit
zwei bzw. drei Stufen. Die Forscher haben nun die
Versuchspersonen (n = 10) als Between-Faktor in die ANOVA mit
hineingenommen, so dass es eine 10x2x3-ANOVA ist. Irgendwie
habe ich das Gefühl, dass das gar keinen Sinn macht, da die
Unterschiede zwischen den Versuchspersonen doch eh schon durch
die Messwiederholung berücksichtigt werden, oder?
VP als fixen Faktor mit in die Analyse aufzunehmen würde wirklich die between-Varianz schätzen, aber einerseits ist die nicht besonders interessant - man ist ja eher an der between-treatment-Var interessiert - und zum anderen haätte das Modell dann genausoviele Faktorstufen wie Messungen, womit das Modell nicht mehr schätzbar ist.
Man kann aber die VP als genesteten Faktor innerhalb des treatments einfliessen lassen, um die Korrelationsstruktur innerhalb der VP besser zu berücksichtigen. Dann ist es aber kein 10x2x3 Design mehr, sondern nur noch ein 2x3.
So wie du es beschreibst klingt es aber auch so, als würde jede VP beide treatments bekommen. Dann läge eigentlich ein cross-over design mit repeated measurements vor … ?
Ich denke mal, dass die Herren da etwas unpräzise waren.
Aus einer Abbildung geht hervor, dass die AV mit dem
Standardfehler korreliert ist (hohe Ausprägung der AV geht mit
großem Standardfehler einher). Hat dies irgendwelche
Ausirkungen auf die Validität der Ergebnisse? Habe ich es
richtig verstanden, dass der SF des Mittelwerts angibt, wie
stark der empirische Mittelwert vom Populationsmittelwert
abweicht, also im Endeffekt die Reliabilität der Schätzung
angibt?
Es sagt dir ersteinmal, dass die Schätzung des MW mit größer werdenden AV schlechter wird. Das hat für das Modell zur Folge, dass die (möglichen) Effekte verwischt werden. Valide ist die stat. Auswertung dennoch, solange das Modell passt.
Du kannst dir mal den CV ansehen. Wenn der konstant ist über alle Messungen ist weitgehend okay, falls es sich um einen Parameter handelt, der nut positive Werte annehmen kann und dessen niedrigster Wert nahe dem LOQ ist.
So wie du es beschreibst klingt es aber auch so, als würde
jede VP beide treatments bekommen. Dann läge eigentlich ein
cross-over design mit repeated measurements vor … ?
Ich denke mal, dass die Herren da etwas unpräzise waren.
Ja, jede VP bekommt alle 6 (also 2x3) Treatments.
VP als fixen Faktor mit in die Analyse aufzunehmen würde
wirklich die between-Varianz schätzen, aber einerseits ist die
nicht besonders interessant - man ist ja eher an der
between-treatment-Var interessiert - und zum anderen haätte
das Modell dann genausoviele Faktorstufen wie Messungen, womit
das Modell nicht mehr schätzbar ist.
Wenn ich die Forscher richtig verstanden habe (Chinesen: schreckliches Englisch) hat jede der 10 VP einen Mittelwert pro Zelle, also gibt es insgesamt 60 Mittelwerte und der Plan hat auch 60 Zellen.
Man kann aber die VP als genesteten Faktor innerhalb des
treatments einfliessen lassen, um die Korrelationsstruktur
innerhalb der VP besser zu berücksichtigen. Dann ist es aber
kein 10x2x3 Design mehr, sondern nur noch ein 2x3.
Was ist denn ein genesteter Faktor?
Es sagt dir ersteinmal, dass die Schätzung des MW mit größer
werdenden AV schlechter wird. Das hat für das Modell zur
Folge, dass die (möglichen) Effekte verwischt werden. Valide
ist die stat. Auswertung dennoch, solange das Modell passt.
Du kannst dir mal den CV ansehen. Wenn der konstant ist über
alle Messungen ist weitgehend okay, falls es sich um einen
Parameter handelt, der nut positive Werte annehmen kann und
dessen niedrigster Wert nahe dem LOQ ist.
Ich weiß nicht, was Du mit CV und LOQ meinst. Ich bin kein Mathematiker, sondern (angehender) Psychologe
Wenn ich die Forscher richtig verstanden habe (Chinesen:
schreckliches Englisch) hat jede der 10 VP einen Mittelwert
pro Zelle, also gibt es insgesamt 60 Mittelwerte und der Plan
hat auch 60 Zellen.
Dann wäre jetzt noch interessant zu wissen, wie die treatments verabreicht wurden: AAABBB bzw. BBBAAA oder kreuz und quer durcheinander? (ABABAB oder AABBAB oder ABBBAA …). Steht da irgendetwas von einer treatment-sequence?
zund dann haben die nochmals Mittelwerte pro VP? D.h. innerhalb eines treatments und eines Intervallshaben die dann auch wieder widerholte Messungen gemacht?
Man kann aber die VP als genesteten Faktor innerhalb des
treatments einfliessen lassen, um die Korrelationsstruktur
innerhalb der VP besser zu berücksichtigen. Dann ist es aber
kein 10x2x3 Design mehr, sondern nur noch ein 2x3.
Was ist denn ein genesteter Faktor?
Das ist ein Faktor der in einem anderen enthalten ist. A(B) bedeutet A genested in B und beschreibt den Sachverhalt, wenn nicht alle level von A in allen Leveln von B vorkommen. Das dient dazu, die Varianz von B noch besser zu zerlegen.
Ich weiß nicht, was Du mit CV und LOQ meinst. Ich bin kein
Mathematiker, sondern (angehender) Psychologe
CV ist der Variationskoeffizient, also der Quotient aus SD und mean. LOQ ist das lower limit of quantification.
Dann wäre jetzt noch interessant zu wissen, wie die treatments
verabreicht wurden: AAABBB bzw. BBBAAA oder kreuz und quer
durcheinander? (ABABAB oder AABBAB oder ABBBAA …). Steht da
irgendetwas von einer treatment-sequence?
Nein, da steht nichts, und ich denke auch nicht, dass die die Reihenfolgen ausbalanciert haben (wie auch, bei 10 VP und 6 Bedingungen)
zund dann haben die nochmals Mittelwerte pro VP? D.h.
innerhalb eines treatments und eines Intervallshaben die dann
auch wieder widerholte Messungen gemacht?
Die VP mussten eine Aufgabe bearbeiten (ich sag mal einfach 5 Minuten lang), dabei wurde ihre Pupillengröße (= AV) mit einem Oszillographen aufgezeichnet. Dann haben die sich immer 5-sekündige Ausschnitte angesehn und MW gebildet. Ich denke die hatten dann em Ende ganz viele dieser Mittelwerte und haben diese wiederum gemittelt.
CV ist der Variationskoeffizient, also der Quotient aus SD und
mean. LOQ ist das lower limit of quantification.
Die Forscher geben keine Zahlenwerte an, so dass ich den CV leider nicht berechnen kann.
Also, wenn ich Dich richtig verstanden habe, ist es nicht „falsch“, die VP als 10-stufigen Faktor mit einzubauen?
Nein, da steht nichts, und ich denke auch nicht, dass die die
Reihenfolgen ausbalanciert haben (wie auch, bei 10 VP und 6
Bedingungen)
Also gehe ich mal davon aus, dass sie alle dieselbe Reihenfolge haben. Ich vermute mal ABABAB für die eine Hälfte und BABABA für die andere, das wäre zumindest sinnvoll (und balanciert).
Die VP mussten eine Aufgabe bearbeiten (ich sag mal einfach 5
Minuten lang), dabei wurde ihre Pupillengröße (= AV) mit einem
Oszillographen aufgezeichnet. Dann haben die sich immer
5-sekündige Ausschnitte angesehn und MW gebildet. Ich denke
die hatten dann em Ende ganz viele dieser Mittelwerte und
haben diese wiederum gemittelt.
Ziemlich stark zusammegefasste Werte … über diese Problematik reden wir lieber erstmal nicht … von wann ist die Studie?3
CV ist der Variationskoeffizient, also der Quotient aus SD und
mean. LOQ ist das lower limit of quantification.
Die Forscher geben keine Zahlenwerte an, so dass ich den CV
leider nicht berechnen kann.
Aus der Grafik kannst du das in etwa schätzen.
SE=SD/√n und
CV=SD/mean
also: CV=√n*SE / mean.
Also, wenn ich Dich richtig verstanden habe, ist es nicht
„falsch“, die VP als 10-stufigen Faktor mit einzubauen?
Doch. Wenn es 60 Messwerte gibt und genausoviele Faktorstufen (im Grunde sogar egal aus wievielen Faktoren), dann ist das Modell perfekt geschätzt, weil zu jeder Stufe eine Schätzung gemacht wird. Da ein VP nur einen Wert pro treatment und Zeiteinheit hat, wird dann der Wert durch sich selbst geschätzt (das ist ja der perfekte fit) und man hat keine Streuung mehr (und keine Freiheitsgrade) um eine Analyse zu machen. Von daher denke ich, dass der Begriff der Forscher undglücklich / falsch gewählt ist und nicht den wahren Sachverhalt beschreibt, da sie ja Resultate angeben.
Ausgehend von obiger Sequenz kann man dann die VP in der Sequenz nesten und so die Varianz innerhlab der Sequenz richtig aufdröseln.
„SD of Mean“ bedeutet doch Standardfehler des MW, oder? Das ist aber merkwürdig, dass die Fehlerbalken (SD/Wurzel(n)) größer sind als die SD-Balken selbst.
Wenn ich lese was Du so schreibst merke ich erstmal, wie beschränkt meine Methoden-Kenntnisse sind. Aber irgendwo muss es ja auch einen Unterschied machen, ob man Mathe oder Psychologie studiert
Ich finds jedenfalls echt super, dass Du mir hier hilfst. Kannst Du mir vielleicht noch ein Buch empfehlen, mit dem ich mich in diesem Bereich weiterbilden könnte?
Das hilft schon mal weiter.
Dein concern mit den SE’s kann man in der Grafik erkennen. I.a. würde ich mich über einen SE zwischen 0.5 und 1.5 nicht sonderlich aufregen, aber in diesem Fall ist wirklich ein trend zu erkennen, wenngleich auch nur in der (-)-Gruppe. Das Ganze sieht eh nach „Regression to the mean aus“, also eine Art Gewöhnungseffekt. Unter diesem Gesichtspunkt solltest du die Studie insgesamt betrachten (was du ja aber eigentlich schon tust).
„SD of Mean“ bedeutet doch Standardfehler des MW, oder? Das
ist aber merkwürdig, dass die Fehlerbalken (SD/Wurzel(n))
größer sind als die SD-Balken selbst.
Ja, das ist wirlich seltsam. Ich denke mal, dass die in Wirkichkeit 2*SD als Fehlerbalken angegeben haben oder sogar ein CI angibt.
Wenn ich lese was Du so schreibst merke ich erstmal, wie
beschränkt meine Methoden-Kenntnisse sind. Aber irgendwo muss
es ja auch einen Unterschied machen, ob man Mathe oder
Psychologie studiert
Danke für die Blumen
Ich finds jedenfalls echt super, dass Du mir hier hilfst.
Kannst Du mir vielleicht noch ein Buch empfehlen, mit dem ich
mich in diesem Bereich weiterbilden könnte?
Wer fragt soll Antwort bekommen.
Kommt drauf an, zu welcher Thematik du ein Buch willst.
Zu der Tabelle: Die müssen mehrere Messungen pro Subject vorliegen haben, anders können die das nicht hinbekommen haben, dass es Schätzer für subject gibt.
Kannst Du mir vielleicht noch ein Buch empfehlen, mit dem ich
mich in diesem Bereich weiterbilden könnte?
Wer fragt soll Antwort bekommen.
Kommt drauf an, zu welcher Thematik du ein Buch willst.
Wichtig wären die Dinge, die im psychologischen „Alltag“ vorkommen, also alle Arten von Varianz- und Regressionsanalysen, vielleicht auch Zeitreihenanalyse. Standardwerk ist wohl der Bortz, von dem ich aber gehört habe, dass es eher ein Nachschlagewerk als ein Lehrbuch ist.
Wichtig wären die Dinge, die im psychologischen „Alltag“
vorkommen, also alle Arten von Varianz- und
Regressionsanalysen, vielleicht auch Zeitreihenanalyse.
Standardwerk ist wohl der Bortz, von dem ich aber gehört habe,
dass es eher ein Nachschlagewerk als ein Lehrbuch ist.
Ja, das stimmt. Vor allem muss man beim Bortz auch immer mal wieder schauen, wie alt das Ganze ist. Oft gibt es da schon neuere/bessere Verfahren.
Ein gutes Einsteigerwerk für Varianz und Regressionsrechnung ist: http://www.amazon.de/Multivariate-Analysemethoden-Ei…
Bei Zeitreihen habe nichts zur Hand.
Wegen repeated measurements, Hypothesentesten, Covarianzstrukturen und so weiter würde ich dir einen Kurs dazu empfehlen (jede größere Uni bietet so etwas an), weil es dazu dutzendfach Literatur in allen Schattierungen gibt, die dann aber auch nicht wieder alles beantwortet.


{kind=link}