Hi wie kann man Duplikate mit einer unterschiedlichen Reihe löschen?
Das Duplikat mit keinen Status soll gelöscht werden.
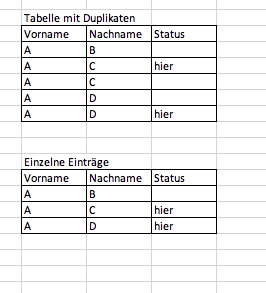
Jedoch sollen auch einzelne Einträge bleiben, die keinen Status haben. Hier ist ein Bsp Bild dazu, wie das Ergebnis aussehen soll.
Moin,
in Südostwestfalen (GH Paderborn) arbeitet man an der Methode
„Wenn ja, dann nich;
wenn nein, dann doch;
sonst wohl“.
Wie weit sie sind, weiß ich jetzt nicht. Problem: Sie finden keinen Namen dafür.
Gruß
Ralf
2 „Gefällt mir“
![]()
![]()
![]()
Ja ich weiß nicht wie es funktionieren soll.
Select Distinct geht nicht Group by or inner Join?
Gibt es eine Möglichkeit? ![]()
Hi,
es geht nicht darum, irgendwelche Buzzwords zu droppen, sondern um das Formulieren der Anforderung in einfachen Worten.
Wenn das nicht gelingt, gibt es wohl auch keine Möglichkeit, die Query in SQL auszudrücken.
Gruß
Ralf
1 „Gefällt mir“
Hi,
wenn ich die Bilder richtig interpretiere, sollen alle Zeilen gelöscht werden, die keine Eintragung beim Status haben, sofern es auch Zeilen mit Eintragungen bei Status gibt, die in den restlichen Spalten mit der Zeile mit Status übereinstimmen.
Gruß
Christa
Naja ![]() deshalb habe ich ja ein Bild hinzugefügt, welches zeigen soll wie das Ergebnis aussehen soll.
deshalb habe ich ja ein Bild hinzugefügt, welches zeigen soll wie das Ergebnis aussehen soll.
Einfacher beschreiben?
Naja ich möchte alle Einträge einmalig behalten.
Wenn aber jetzt ein Eintrag mit und ohne Status vorhanden ist, möchte ich nur den Eintrag mit dem Status behalten.
Ist ein Eintrag jedoch nur ohne Status vorhanden, soll der Eintrag ohne Status bleiben.
Klingt das logisch?
Ja stimmt genau.
Nur das verwirrt mich.
Ich habe meinen Beitrag korrigiert, hatte ein falsches Wort benutzt.
Danke Christa, ja so stimmt`s genau, jetzt bräuchte ich nur noch eine Lösung dazu.
Mich würde erstmal der Sinn des Ganzen interessieren. Du bist seit Tagen dabei, irgendwelche Sachen zu löschen, vielleicht wäre es einfacher, die Tabellen neu anzulegen!
Ja ich fasse gerade 3 Tabellen zu einer neuen Tabelle zusammen.
Genau das möchte ich mit diesen Query machen.
Hi.
suche die Zeilen, deren Gruppe (Vorname, Name) öfter als einmal vorkommt. Aus dieser Menge alle die löschen, deren Status leer ist. Noch Fragen?
Servus
Ralf
Danke Ralf, nachdem ich mehrere Stunden verbracht habe, konnte ich es mit Hilfe von anderen Lösen:
SELECT Vorname, Nachname, MAX(Status) FROM table
GROUP BY Vorname, Nachname
HAVING MAX(status) IS NOT NULL;
So wäre das eine einfache und leichte AW gewesen.
Tja, das ist Deine SQL-Lösung, ich hätte eine ganz andere gehabt. Gelernt hättest Du dabei eher wenig.
Gruß
Ralf
Was liefert „max(status)“, und warum willst du den Höchstwert, wenn es dir nur darum ging, ob Status überhaupt irgendeinen Wert hat oder nicht?
(hatte ich vorhin übersehen)
Ach wass - so leicht und einfach?
Gruß
Ralf
Zusatzfrage: Kommt Deine Lösung auch mit mehreren Ausprägungen von STATUS zurecht?
Gruß
Ralf
Servus, Christa,
was ich schon befürchtet habe: Mit Max(Status) kriegt er nur den höchsten. Bei mehr als einer Ausprägung landen die kleineren Werte im Nirwana.
Wo gibt es schon einen einzigen Status-Wert, da würde ein Boolean langen.
Gruß
Ralf
Hallo Ralf,
nun ja, wenn er „seine“ Lösung so toll findet und keine weiteren Infos liefert, soll er halt damit glücklich werden! ![]() Ich habe auch keine Lust, ihm alles aus der Nase zu ziehen.
Ich habe auch keine Lust, ihm alles aus der Nase zu ziehen.
Viele Grüße
Christa
Danke @Christa & @drambeldier klar stimmt es das Ralf recht hat!
Mit mehreren Status Meldungen kommt das Query leider nicht zu recht.
Deshalb versuch ich immer die einfachste und schnellste Lsg zu finden und wenn ich keine einfache AW finde versuche ich einfach den einfachsten Weg zu gehen um an die Lsg zu kommen…
(Eleminiere alle Status bis auf einen und verwende dann den Query)
Danke Merci Gracias euch beiden für die oft schnellen Lösungen!
Ihr seit toll.